Migrating Our Database | ChartMogul


TL;DR
We sharded one of the core ChartMogul databases and changed its tables’ partitioning scheme from LIST to HASH. This way we managed to:
- Remove a single point of failure (SPOF) from our architecture
- At least triple query performance
- Reduce AWS RDS costs by 10%, and
- Eliminate all incidents deriving from that part of the system
Context
ChartMogul receives millions of webhooks from various billing systems daily, normalizes and stores them in aggregated tables, and then presents subscription analytics as metrics and charts. This is a full scale extract-transform-load (ETL) process, with various modules performing different data transformations and storing data into their corresponding databases, as presented in the figure below:
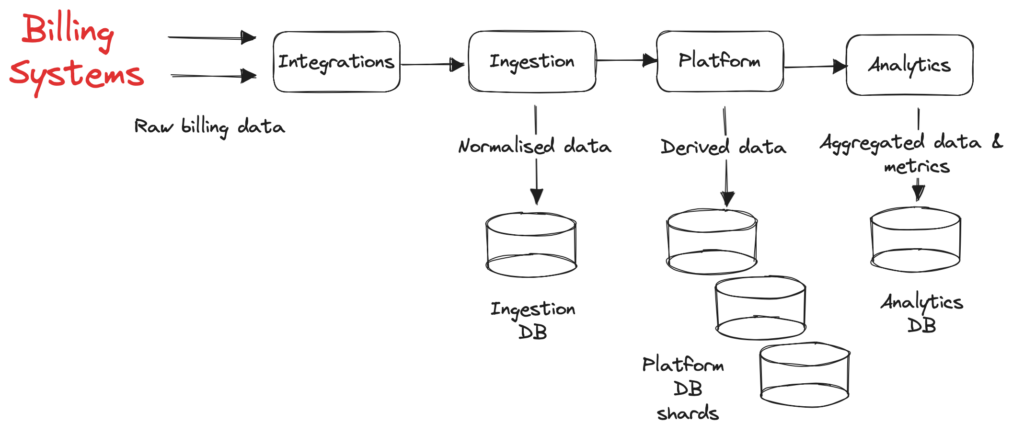
We migrated to AWS over a year ago, and most modules of ChartMogul’s application are part of a Ruby on Rails monolith using Sidekiq for background job processing and AWS RDS (Postgres) for the aforementioned databases. A few years ago, ChartMogul was in hyper growth, which increased the volume of processed and stored data. To handle the increasing load, ChartMogul engineers decided to horizontally scale the platform database by adding more shards.
However, the ingestion database continued to operate under a single Postgres instance (and a read replica) as it was already partitioned using Postgres’ LIST partitioning scheme. Ingestion database tables were partitioned based on the account_id column (a unique internal identifier of each ChartMogul account) and each account received a partition per table in that database. As ChartMogul continued to grow with an increasing number of accounts and more complex integrations and features, LIST partitioning became unsustainable. Despite temporary mitigations to group most accounts under default partitions or scale up the instance (and increase the associated costs), we encountered incidents caused by:
- Extreme read IOPS due to heavy queries processing hundreds of thousands or millions of records,
- Out of memory issues due to large and inefficient indexes
- Stale Postgres statistics requiring regular vacuum operations
- Administrative tasks related to partitions: attaching or detaching some partitions caused ACCESS EXCLUSIVE locks on the parent table
Despite continued efforts to optimize these queries and tasks, fine-tune the AWS RDS parameters, and optimize the normalization processing code, that specific instance was still a SPOF for our application and the most expensive AWS RDS instance. So in late 2022, we decided to migrate its tables under the sharded platform database and leverage from that scaled architecture to:
- Remove the SPOF and reduce costs
- Have smaller tables and indexes
- Optimize performance, and
- Reduce incidents
Decisions
The first decision we made was easy: replace LIST with HASH partitioning [4] for the migrated tables. The main advantage is we mix big and small accounts randomly and we don’t have to do manual interventions. The only point of debate was the number of partitions, taking into account our current distribution, future load, and the need to change their number again (which we wanted to avoid). After some thorough simulation we opted for 30 partitions for our largest table, which would result in tables of ~2.5GB (95% percentile).
As for the migration tool, a few options were on the table. Internal tools had been developed to migrate tables and data between databases but these were operated on account level and were only used for offline migrations. However, our goal was to migrate the whole database with zero downtime, so we quickly discarded this option.
AWS Database Migration Service (DMS) was the next option; it’s the standard tool for live database migrations in AWS as it supports batch and incremental loading. We expected it would be very efficient for a Postgres to Postgres migration on identical tables, and we wouldn’t have to deal with inconsistent data types or other usual conflicts that come up in a cross-database migration. Our only additional requirement would be migrating from a single database into five different ones, hence the need to apply relevant rules to filter data either based on the partitioned table list or the account_id column. After verifying that AWS DMS supports both types of rules, we did some quick experimentation in our beta environment and with production clones before agreeing to move forward with this approach.
We have five platform shards, so we decided to migrate accounts to their corresponding shard, ideally one shard per day. This method would allow us to thoroughly check for issues on the first migrated shard, and fine-tune DMS settings before migrating the remaining shards. This way, we could avoid the overhead and potential performance issues from starting five replication slots in a running database to support five concurrent migration tasks.
Migration
We planned for the migration to take a week. The first task was to migrate the ingestion-related code to work in a sharded-database context under a feature flag. This would ensure that the batch of migrated accounts only utilized the platform database when they had their feature flag set. We created the new tables and partitions for each platform shard excluding the indexes, as these would slow down batch loading according to AWS DMS recommendations. Code was also updated to redirect new accounts’ ingestion data directly into the platform database, which meant we would only have to migrate data for existing accounts.
Next, we prepared a script which would generate the AWS DMS rules for all accounts to be migrated in one shard. The script would prepare table rules based on table partition (if the account had a separate one) or column rules on the default partition. The initial run for a single shard produced a JSON file with size >2MB, which would reach AWS API limits and was not recommended by AWS DMS documentation. We had to fine-tune it to only consider accounts with data in any of the tables being migrated.
Each shard followed this checklist:
We timed the migration on a production clone and the end-to-end flow would require two hours with pessimistic batch load task settings (4 tables in parallel, 50k rows batch size) not to overload the live platform database shard.
We ran the first migration on the shard where the ChartMogul account is persisted. Batch loading completed successfully within two hours, except for one small table which failed with no meaningful error logs. Luckily, the table was easy to migrate by exporting and importing with pg_dump while Sidekiq was down. We later found out that some code was updating both the shard and the original database, which led to failed synchronization. Fortunately, this was just a timestamp and had no impact on data. Another issue was our chosen AWS DMS settings for batch loading caused high CPU usage on the platform shard, impacting front-end response time. We lowered them even further to 3 tables and 30k rows batch size and increased the batch loading time to 3–4 hours to ensure the front end would not be impacted.
Despite these hiccups, audits were green, query performance was great, and our checks to selected test accounts passed, so we were 100% confident this would work smoothly in all shards. As planned, we successfully migrated all five shards within a week. Afterwards, the team removed all references of the ingestion database from the codebase, and removed the unnecessary feature flag. 5,000 lines of code (LOC) were deleted.
Results
Our updated architecture is presented in the following figure:
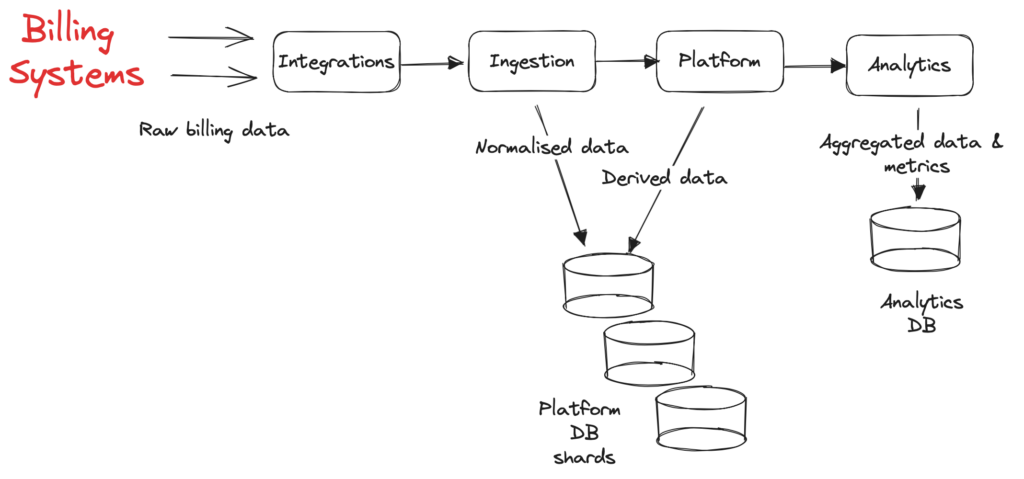
After the successful migration we measured 5× improvement in simple select queries and 3× improvement in select queries with joins, while most of the table partitions were below 3GB each. Before, ingestion-related queries were among the top five heavy queries in our AWS RDS Performance Insights, now, they don’t even appear on the list. The ingestion and its replica instances were made obsolete, resulting in reduced AWS RDS costs by 10% by removing the most expensive instance (and its replica) from our system. Most importantly, incidents related to data normalization have been eliminated since April 2023.
Over the years, our team has transitioned from committing to solutions with a ‘quick fix’ to taking a more deliberate approach by engaging in RFC discussions, and performing PoCs. Our recent migration was a testament to this transformation, demonstrating the success of the ChartMogul engineering team.
In upcoming posts, we’ll explore various engineering and data architecture topics: ongoing migrations, and our strategic approach to scaling our crucial database, the analytics DB (which currently serves as our last SPOF).
Other links
ChartMogul Import API: https://dev.chartmogul.com/reference/introduction-import-apiChartMogul data model: https://dev.chartmogul.com/docs/system-overview
