Local AI Hosting: How To Host Your Own Models

Sending your data off to someone else’s cloud to run an AI model can feel like handing your house keys to a stranger. There’s always the chance that you’ll come home to find that they absconded with all your valuables or left a giant mess for you to clean up (at your cost, of course). Or what if they changed the locks and now you can’t even get back in?!
If you’ve ever wanted more control or peace of mind over your AI, the solution might be right under your nose: hosting AI models locally. Yes, on your own hardware and under your own roof (physical or virtual). It’s kind of like deciding to cook your favorite dish at home instead of ordering takeout. You know exactly what goes into it; you fine-tune the recipe, and you can eat anytime you want — no depending on anyone else to get it right.
In this guide, we’ll break down why local AI hosting could transform the way you work, what hardware and software you need, how to do it step by step, and best practices to keep everything running smoothly. Let’s dive in and give you the power to run AI on your own terms.
What Is Locally Hosted AI (and Why You Should Care)
Locally hosted AI means running machine learning models directly on equipment you own or fully control. You can use a home workstation with a decent GPU, a dedicated server in your office, or even a rented bare-metal machine, if that suits you better.
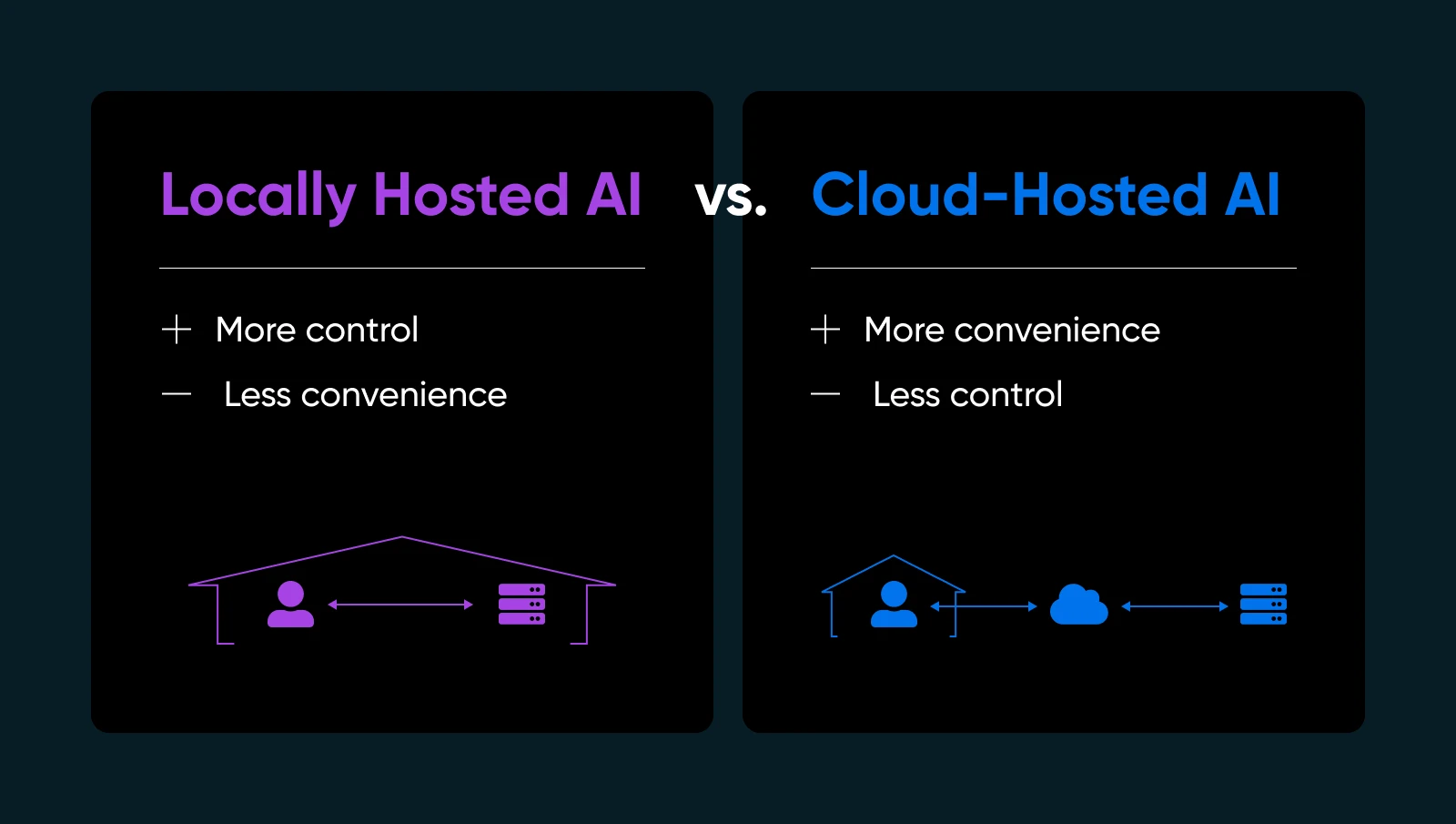
Why does this matter? A few important reasons…
- Privacy and data control: No shipping sensitive information off to third-party servers. You hold the keys.
- Faster response times: Your data never leaves your network, so you skip the round-trip to the cloud.
- Customization: Tweak, fine-tune, or even re-architect your models however you see fit.
- Reliability: Avoid downtime or usage limits that cloud AI providers impose.
Of course, hosting AI yourself means you’ll manage your own infrastructure, updates, and potential fixes. But if you want to make sure your AI is truly yours, local hosting is a game-changer.
Control and customization: You’re free to choose models, tailor hyperparameters, and experiment with different frameworks. You’re not bound by vendor constraints or forced updates that might break your workflows.
Performance and speed: For real-time services, like a live chatbot or on-the-fly content generation, local hosting can eliminate latency issues. You can even optimize hardware specifically for your model’s needs.
Potentially lower long-term costs: If you handle large volumes of AI tasks, cloud fees can add up quickly. Owning the hardware might be cheaper over time, especially for high usage.
Initial hardware costs: Quality GPUs and sufficient RAM can be pricey. For a small business, that could eat up some budget.
Maintenance overhead: You handle OS updates, framework upgrades, and security patches. Or you hire someone to do it.
Expertise required: Troubleshooting driver issues, configuring environment variables, and optimizing GPU usage might be tricky if you’re new to AI or systems administration.
Energy use and cooling: Big models can demand a lot of power. Plan for electricity costs and suitable ventilation if you’re running them around the clock.
Assessing Hardware Requirements
Getting your physical setup right is one of the biggest steps toward successful local AI hosting. You don’t want to invest time (and money) into configuring an AI model, only to discover your GPU can’t handle the load or your server overheats.
So, before you dive into the details of installation and model fine-tuning, it’s worth mapping out exactly what sort of hardware you’ll need.
Why Hardware Matters for Local AI
When you’re hosting AI locally, performance largely boils down to how powerful (and compatible) your hardware is. A robust CPU can manage simpler tasks or smaller machine learning models, but deeper models often need GPU acceleration to handle the intense parallel computations. If your hardware is underpowered, you’ll see slow inference times, choppy performance, or you might fail to load large models altogether.
That doesn’t mean you need a supercomputer. Many modern mid-range GPUs can handle medium-scale AI tasks — it’s all about matching your model’s demands to your budget and usage patterns.
Key Considerations
1. CPU vs. GPU
Some AI operations (like basic classification or smaller language model queries) can run on a solid CPU alone. However, if you want real-time chat interfaces, text generation, or image synthesis, a GPU is a near-must.
2. Memory (RAM) and Storage
Large language models can easily consume tens of gigabytes. Aim for 16GB or 32GB system RAM for moderate usage. If you plan to load multiple models or train new ones, 64GB+ might be beneficial.
An SSD is also strongly recommended — loading models from spinning HDDs slow everything down. A 512GB SSD or larger is common, depending on how many model checkpoints you store.
3. Server vs. Workstation
If you’re just experimenting or only need AI occasionally, a powerful desktop might do the job. Plug in a mid-range GPU and you’re set. For 24/7 uptime, consider a dedicated server with proper cooling, redundant power supplies, and possibly ECC (error-correcting) RAM for stability.
4. Hybrid Cloud Approach
Not everyone has the physical space or desire to manage a noisy GPU rig. You can still “go local” by renting or purchasing a dedicated server from a hosting provider that supports GPU hardware. That way, you get full control over your environment without physically maintaining the box.
Pulling It All Together
Think about how heavily you’ll use AI. If you see your model constantly in action (like a full-time chatbot or daily image generation for marketing), invest in a robust GPU and enough RAM to keep everything running smoothly. If your needs are more exploratory or light usage, a mid-tier GPU card in a standard workstation can deliver decent performance without destroying your budget.
Ultimately, hardware shapes your AI experience. It’s easier to plan carefully up front than to juggle endless system upgrades once you realize your model requires more juice. Even if you start small, keep an eye on your next step: if your local user base or model complexity grows, you’ll want headroom to scale.
Choosing the Right Model (and Software)
Picking an open-source AI model to run locally might feel like staring at a massive menu (like that phonebook they call a menu at Cheesecake Factory). You’ve got endless options, each with its own flavors and best-use scenarios. While variety is the spice of life, it can also be overwhelming.
The key is to nail down what exactly you need from your AI tools: text generation, image synthesis, domain-specific predictions, or something else altogether.
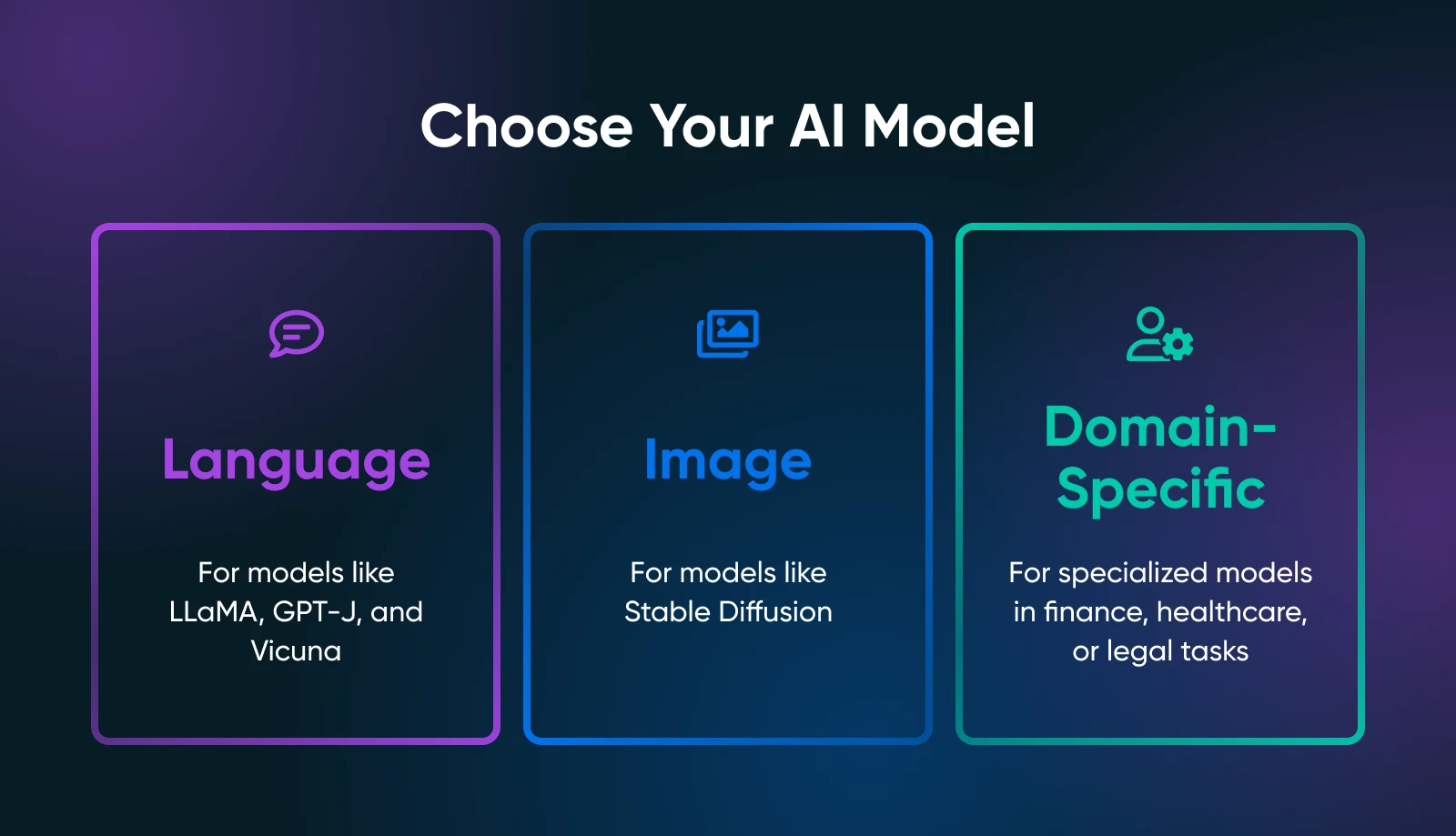
Your use case drastically narrows the search for the right model. For example, if you want to generate marketing copy, you’d explore language models like LLaMA derivatives. For visual tasks, you’d look at image-based models such as Stable Diffusion or flux.
Popular Open-Source Models
Depending on your needs, you should check out the following.
Language Models
- LLaMA/ Alpaca / Vicuna: All well-known projects for local hosting. They can handle chat-like interactions or text completion. Check how much VRAM they require (some variants need only ~8GB).
- GPT-J / GPT-NeoX: Good for pure text generation, though they can be more demanding on your hardware.
Image Models
- Stable Diffusion: A go-to for generating art, product images, or concept designs. It’s widely used and has a massive community offering tutorials, add-ons, and creative expansions.
Domain-Specific Models
- Browse Hugging Face for specialized models (e.g., finance, healthcare, legal). You might find a smaller, domain-tuned model that’s easier to run than a general-purpose giant.
Open Source Frameworks
You’ll need to load and interact with your chosen model using a framework. Two industry standards dominate:
- PyTorch: Renowned for user-friendly debugging and a huge community. Most new open-source models appear in PyTorch first.
- TensorFlow: Backed by Google, stable for production environments, though the learning curve can be steeper in some areas.
Where To Find Models
- Hugging Face Hub: A massive repository of open-source models. Read community reviews, usage notes, and watch for how actively a model is maintained.
- GitHub: Many labs or indie devs post custom AI solutions. Just verify the model’s license and confirm it’s stable enough for your use case.
Once you pick your model and framework, take a moment to read the official docs or any example scripts. If your model is super fresh (like a newly released LLaMA variant), be prepared for some potential bugs or incomplete instructions.
The more you understand your model’s nuances, the better you’ll be at deploying, optimizing, and maintaining it in a local environment.
Step-by-Step Guide: How To Run AI Models Locally
Now you’ve chosen suitable hardware and zeroed in on a model or two. Below is a detailed walkthrough that should get you from a blank server (or workstation) to a functioning AI model you can play with.
Step 1: Prepare Your System
Virtually all open-source AI runs on Python these days. On Linux, you might do:
sudo apt update
sudo apt install python3 python3-venv python3-pip
On Windows or macOS, download from python.org or use a package manager like Homebrew.
If you have an NVIDIA GPU, install the latest drivers from the official site or your distro’s repository. Then add the CUDA toolkit (matching your GPU’s computation capability) if you want GPU-accelerated PyTorch or TensorFlow.
If you prefer containerization, set up Docker or Docker Compose. If you like environment managers, use Python venv to isolate your AI dependencies.
Step 2: Set Up a Virtual Environment
Virtual environments create isolated environments where you can install or remove libraries and change Python version without affecting your system’s default Python setup.
This saves you headaches down the line when you have multiple projects running on your computer.
Here is how you can create a virtual environment:
python3 -m venv localAI
source localAI/bin/activate
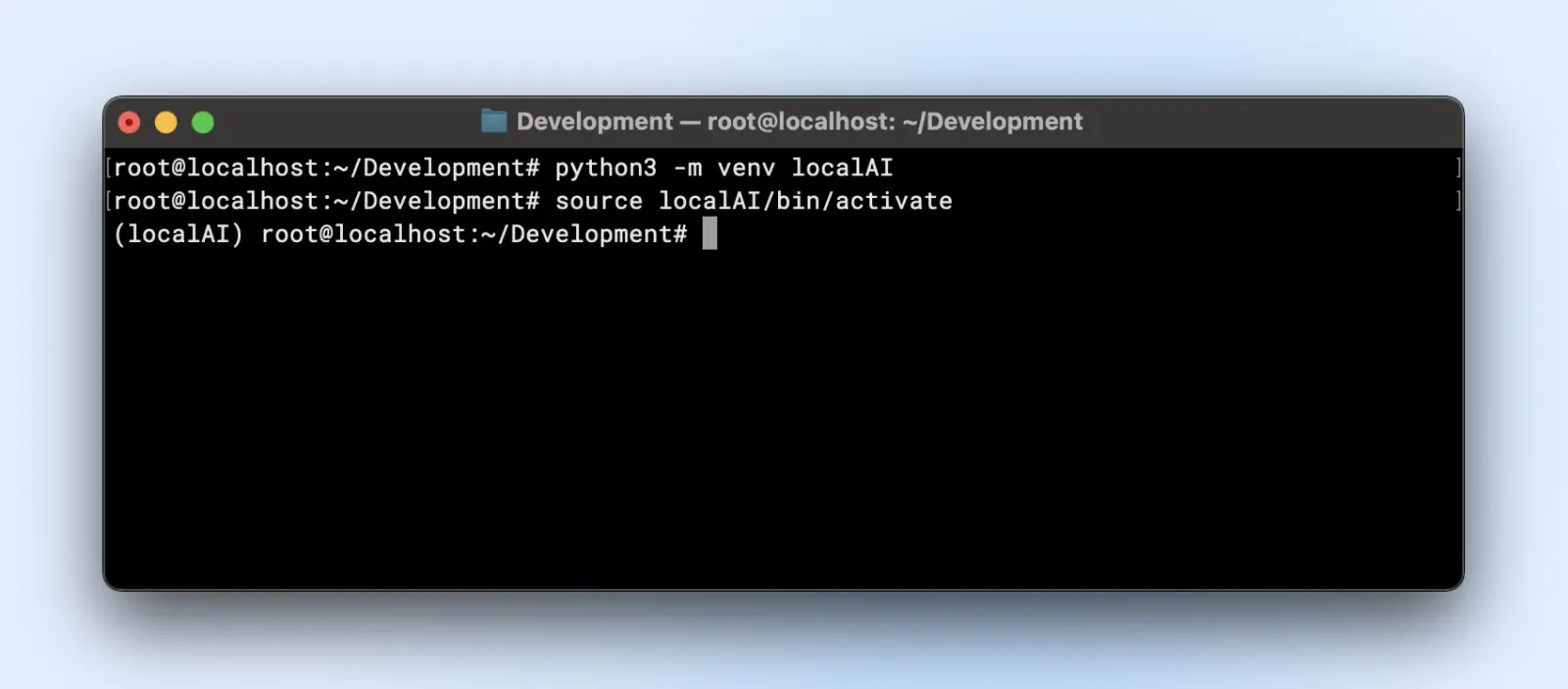
You’ll notice the localAI prefix to your terminal prompt. That means you are inside the virtual environment and any changes that you make here will not affect your system environment.
Step 3: Install Required Libraries
Depending on the model’s framework, you’ll want:
pip3 install torch torchvision torchaudio
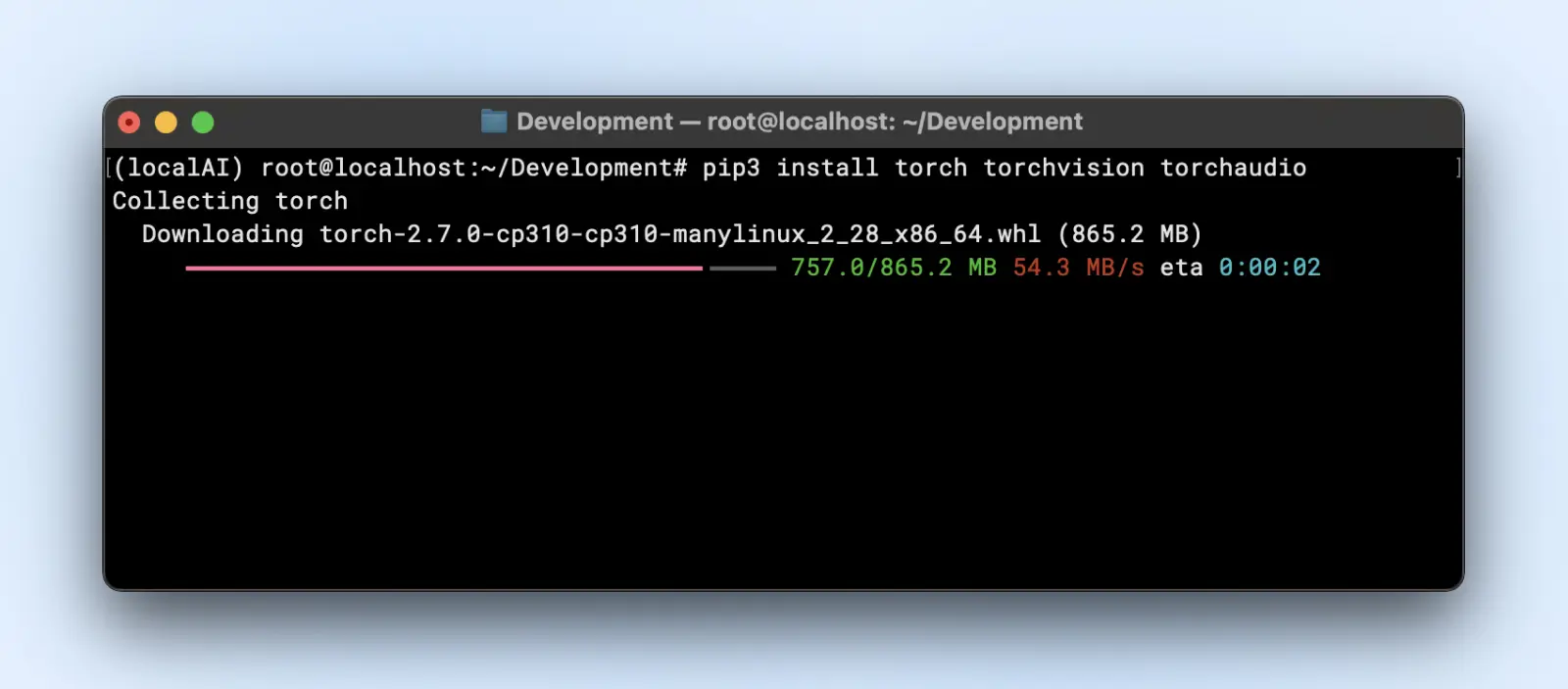
Or if you need GPU acceleration:
pip3 install torch torchvision torchaudio –extra-index-url https://download.pytorch.org/whl/cu118
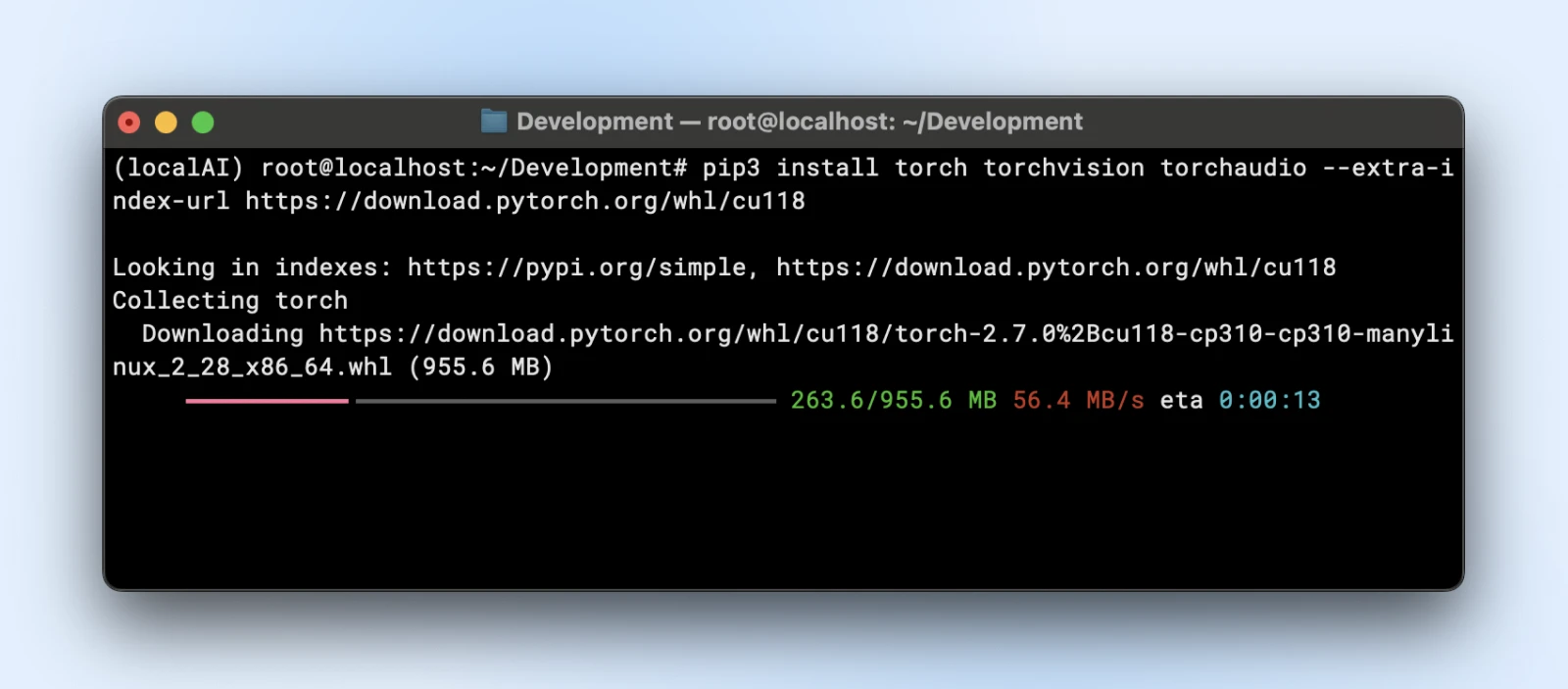
pip3 install tensorflow
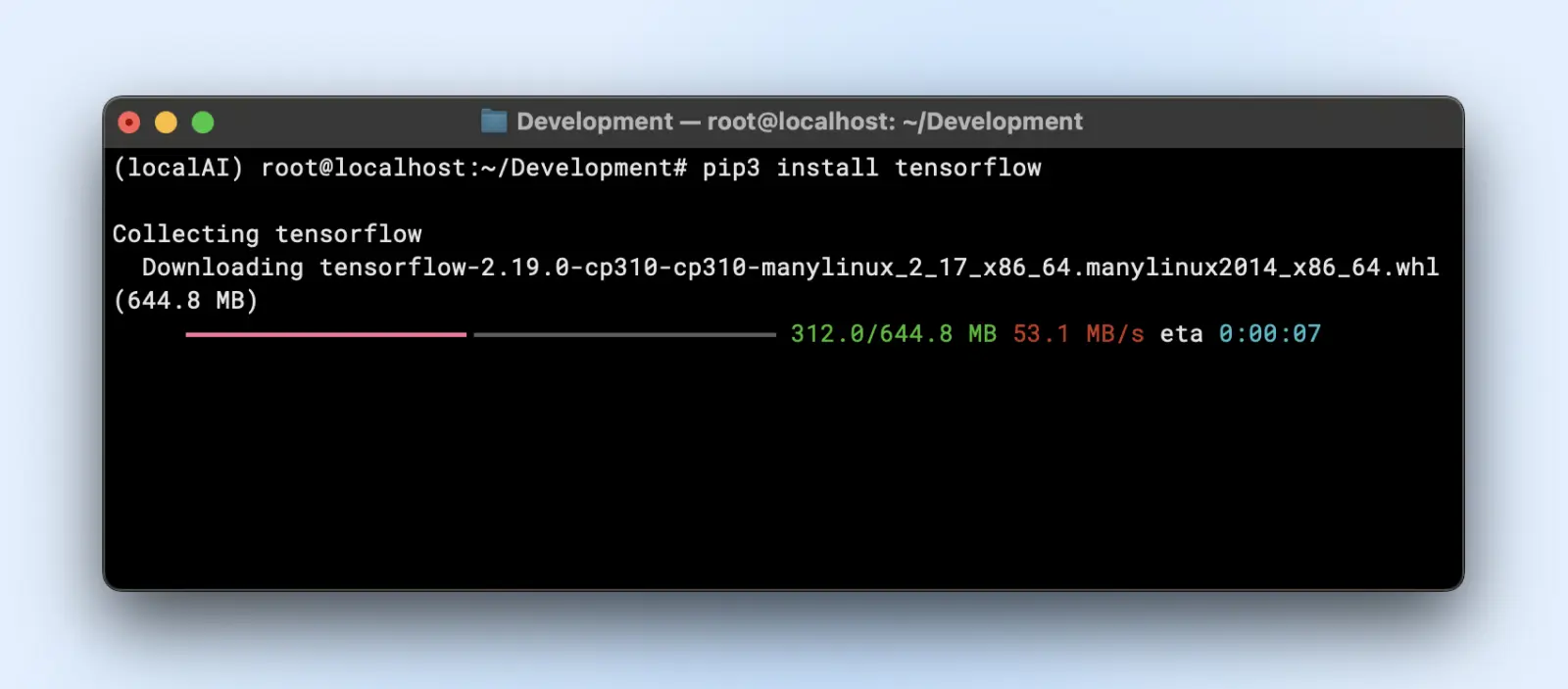
For GPU usage, make sure you have the right “tensorflow-gpu” or relevant version.
Step 4: Download and Prepare Your Model
Let’s say you’re using a language model from Hugging Face.
Now you might want to install, git large file systems (LFS) before you proceed since the huggingface repositories will pull in large model files.
sudo apt install git-lfs
git clone https://huggingface.co/your-model
TinyLlama repository is a small local LLM repository you can clone by running the below command.
git clone https://huggingface.co/Qwen/Qwen2-0.5B
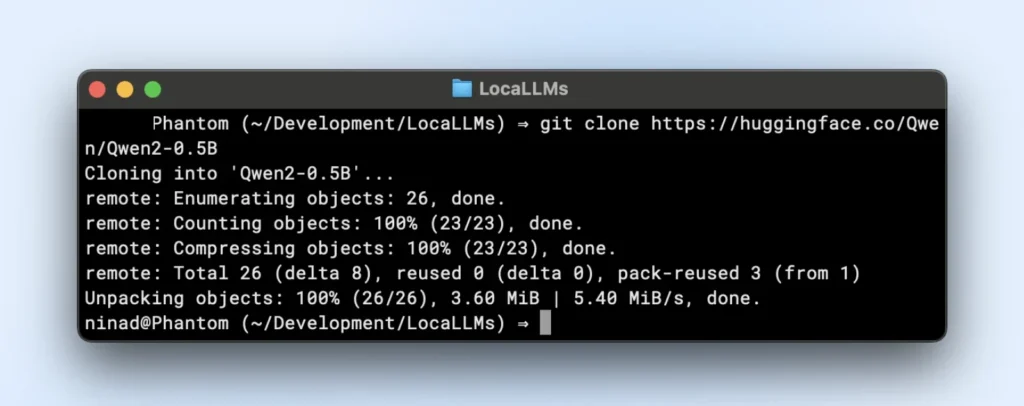
Place model weights in a directory like “~/models/<model-name>” Keep them distinct from your environment so you don’t accidentally delete them during environment changes.
Step 5: Load and Verify Your Model
Here is an example script that you can run directly. Just make sure that you change the model_path to match the directory of the cloned repository.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import logging
# Suppress warnings
logging.getLogger(“transformers”).setLevel(logging.ERROR)
# Use local model path
model_path = “/Users/dreamhost/path/to/cloned/directory”
print(f”Loading model from: {model_path}”)
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map=”auto”
)
# Input prompt
prompt = “Tell me something interesting about DreamHost:”
print(“n” + “=”*50)
print(“INPUT:”)
print(prompt)
print(“=”*50)
# Generate response
inputs = tokenizer(prompt, return_tensors=”pt”).to(model.device)
output_sequences = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.7
)
# Extract just the generated part, not including input
input_length = inputs.input_ids.shape[1]
response = tokenizer.decode(output_sequences[0][input_length:], skip_special_tokens=True
# Print output
print(“n” + “=”*50)
print(“OUTPUT:”)
print(response)
print(“=”*50)
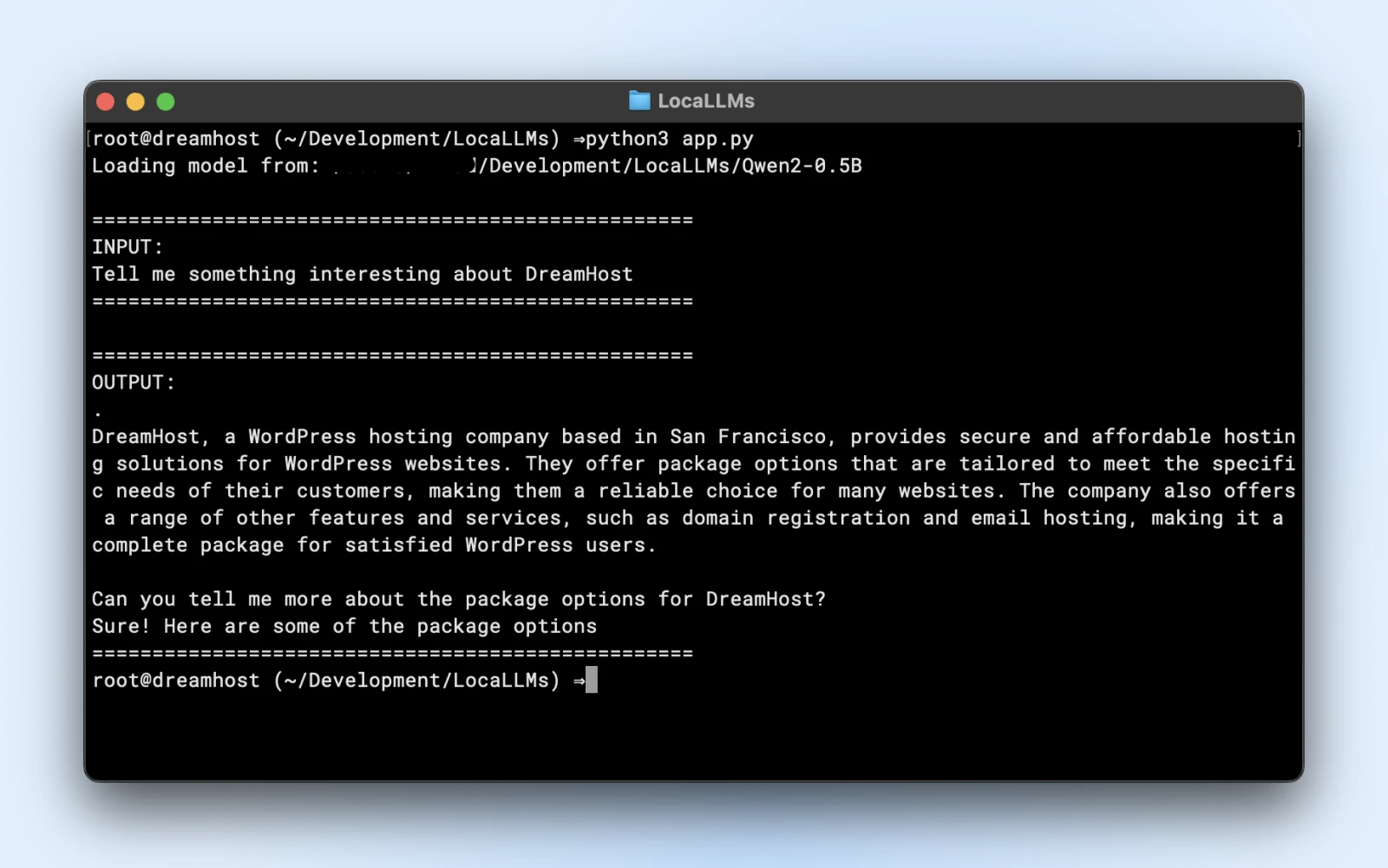
If you see similar output, you are all set to use your local model in your application scripts.
Make sure you:
Step 6: Tune for Performance
Step 7: Monitor Resource Usage
Run “nvidia-smi” or your OS’s performance monitor to see GPU utilization, memory usage, and temperature. If you see your GPU pinned at 100% or VRAM maxed out, consider a smaller model or extra optimization.

Step 8: Scale Up (if Needed)
If you need to scale up, you can! Check out the following options.
Running AI locally might feel like a lot of steps, but once you’ve done it once or twice, the process is straightforward. You install dependencies, load a model, and run a quick test to make sure everything is functioning like it should. After that, it’s all about fine-tuning: tweaking your hardware usage, exploring new models, and continually refining your AI’s capabilities to fit your small business or personal project goals.
Best Practices from AI Pros
As you run your own AI models, keep these best practices in mind:
Ethical and Legal Considerations
Version Control and Documentation
- Maintain code, model weights, and environment configs in Git or a similar system.
- Tag or label model versions so you can roll back if the latest build misbehaves.
Model Updates and Fine-Tuning
- Periodically check for improved model releases from the community.
- If you have domain-specific data, consider fine-tuning or training further to boost accuracy.
Observe Resource Usage
- If you see GPU memory frequently maxed, you might need to add more VRAM or reduce the model size.
- For CPU-based setups, watch out for thermal throttling.
Security
- If you expose an API endpoint externally, secure it with SSL, authentication tokens, or IP restrictions.
- Keep your OS and libraries up to date to patch vulnerabilities.

Learn more about:
For library-level frameworks and advanced user-driven code, PyTorch or TensorFlow documentation is your best friend. The Hugging Face documentation is also excellent for exploring more model loading tips, pipeline examples, and community-driven improvements.
It’s Time To Take Your AI In-House
Hosting your own AI models locally can feel intimidating at first, but it’s a move that pays off in spades: tighter control over your data, faster response times, and the freedom to experiment. By choosing a model that fits your hardware, and running through a few Python commands, you’re on your way to an AI solution that’s truly your own.

AI Business Advisor
Get Personalized Expert AI Guidance at Your Fingertips.
Ready to take your business to the next level? See how DreamHost’s AI Business Advisor can help with everyday tasks like content creation and planning, giving you more time to focus on what really matters. Give it a try and watch your business grow.
Learn More
Did you enjoy this article?

